TL;DR
VigilSAR Benchmark has been introduced as a public, in-development AI model leaderboard focused on deployment factors such as reliability, compliance, robustness and local operation. Its central claim is that there is no single best model because rankings change depending on the buyer and use case.
Thorsten Meyer AI has introduced VigilSAR Benchmark, a public, in-development leaderboard that scores AI models on deployment factors rather than treating raw capability as the only measure of quality, a shift aimed at buyers in regulated, sovereign and defense-adjacent settings.
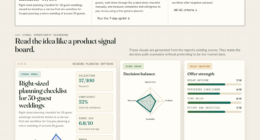
The benchmark rates models across five axes: Capability, Reliability, Robustness, Safety & Compliance, and Efficiency & Deployability. It is also designed to compare performance across eight knowledge domains, according to the source material.
Its main finding is built into the benchmark’s design: the same model can rank first for one buyer profile and lose or be disqualified for another. The example given in the source material shows a cloud-focused profile favoring a frontier model, a sovereign edge profile favoring a model that can run air-gapped on owned hardware, and a compliance-first profile favoring a model aligned with the EU AI Act and GDPR.
Thorsten Meyer AI states that the benchmark covers defense-relevant competence, including domain knowledge, reliability, compliance and deployability. The source material says it explicitly excludes weaponeering, targeting, CBRN and exploit-generation tasks.
VigilSAR Benchmark — there is no best model
Capability leaderboards measure who’s smartest. This one scores who’s deployable — across five axes — then re-ranks by who’s actually asking.
Independent commentary, produced with AI assistance under human editorial oversight. The views are the author’s own and may change. VigilSAR Benchmark is an early-stage, in-development public benchmark; methodology, scope and results will evolve and are not a certification, authority, or guarantee of any model’s fitness, safety, or compliance. It scores defense-relevant competence and explicitly excludes weaponeering, targeting, CBRN, and exploit-generation tasks. Benchmark results are indicative, can be gamed or in error, and require independent verification; nothing here endorses any model. Model and company names are trademarks of their respective owners; mention does not imply endorsement.
Deployment Fit Changes Rankings
The benchmark challenges a common reading of AI leaderboards: that the highest-scoring model on general capability tests is automatically the best choice. For organizations that need to control data, meet legal requirements or operate systems without cloud access, raw capability may be only one part of a purchase or deployment decision.
That matters for public-sector, defense-adjacent and regulated buyers because the consequences of model choice can include data exposure, compliance risk, unstable outputs and infrastructure limits. In those settings, a model that is slightly weaker on broad tests may be more usable if it can run locally, behave consistently and meet legal or policy constraints.
The project’s provider-agnostic framing also matters. Rather than endorsing a single model family or vendor, VigilSAR Benchmark presents the ranking question as conditional: who is asking, what constraints apply, and what deployment environment is allowed.

Asbestos Test Kit – (2 Samples) Emailed Results Within 3 to 5 Business Days – Includes Return Mailer and Expert Consultation. Required Lab Fee for NVLAP Analysis
Easy and Safe Testing: Utilize our asbestos testing kit to safely collect 2 samples for analysis. Simple to…
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Capability Scores Face Limits
AI model leaderboards often center on capability tests that compare model performance across broad task sets. Those rankings can be useful for judging model strength, but they do not usually answer operational questions such as whether a model can run on-premises, withstand unusual inputs, satisfy compliance needs or produce stable responses over repeated runs.
VigilSAR Benchmark is positioned as part of the Thorsten Meyer AI operator portfolio’s Defense / Intel layer and is available through vigilsar.com/benchmark, according to the source material. The announcement describes it as completing the portfolio’s Defense / Intel family.
The source material also frames the benchmark as an early public build rather than a finished authority. It says the methodology, scope and results will change over time and should not be treated as certification, a safety guarantee or proof that any model is fit for a specific use.
“Smartest is not the same as deployable.”
— Thorsten Meyer AI

AI & Edge Computing: Practical Projects for Deploying Machine Learning Models on Raspberry Pi and Local Devices
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Methodology Still In Development
Several details remain unresolved. The source material does not provide final scoring weights, full test design, model list, raw results or an independent validation process. It also does not state how often results will be updated or how benchmark-gaming risks will be handled.
The benchmark’s compliance scoring should also be read carefully. Thorsten Meyer AI describes Safety & Compliance as a scored axis and references EU AI Act and GDPR alignment, but the source material says the benchmark is not a certification or guarantee of legal compliance. Buyers would still need independent technical, legal and security review before relying on any ranking.

AI Productivity for the European Bureaucrat: GDPR-Compliant Workflows That Save 10+ Hours Weekly
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Public Testing Comes Next
The next step is the benchmark’s continued public development. Thorsten Meyer AI says the methodology, scope and results will evolve, meaning future updates are expected to clarify how models are scored, how buyer profiles are weighted and how the benchmark handles contested or changing model claims.
For readers tracking AI procurement, the key test will be whether VigilSAR Benchmark can publish enough transparent evidence to make its rankings useful beyond the initial framing. Until then, its value is clearest as a structured argument: deployment constraints can change the answer to which model is best.
air-gapped AI hardware for secure deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What is VigilSAR Benchmark?
VigilSAR Benchmark is a public, in-development AI model leaderboard from Thorsten Meyer AI that scores models across capability, reliability, robustness, safety and compliance, and efficiency and deployability.
Why does it say there is no best model?
The benchmark ranks models differently depending on the buyer profile. A model suited for cloud deployment may not be the best choice for a buyer that needs air-gapped local operation or stronger compliance alignment.
Does the benchmark test dangerous defense tasks?
No, according to the source material. Thorsten Meyer AI says the benchmark excludes weaponeering, targeting, CBRN and exploit-generation tasks, and focuses on trustworthiness and deployability.
Is VigilSAR Benchmark a certification?
No. The source material says it is early-stage and in development, and that its results are indicative rather than a guarantee of model fitness, safety or compliance.
Who is the benchmark for?
It is aimed at readers and buyers who need to compare AI models under real deployment constraints, including regulated organizations, sovereign users and defense-adjacent teams.
Source: Thorsten Meyer AI